为推动蛋白质组学领域的研发创新,加强国际合作与交流,由人体蛋白质组导航计划(π-HuB)、亚太人类蛋白质组组织(AOHUPO)、亚太农业蛋白质组组织(AOAPO)及中国人类蛋白质组组织(CNHUPO)联合主办,国家蛋白质科学中心(北京)、南方医科大学南方医院、医学蛋白质组学国家重点实验室及广东智慧医学国际研究院协办的 “第十二届亚太人类蛋白质组组织(AOHUPO)大会、第八届亚太农业蛋白质组组织(AOAPO)大会、第三届 π-HuB 全球峰会暨第十三届中国人类蛋白质组组织(CNHUPO)大会”,定于2025年10月11-14日在广州召开。大会主题为 “探索蛋白质宇宙:迈向新生物学与精准医学”。
To promote the research and development of proteomics and enhance international cooperation and exchange, the Joint 12th AOHUPO, 8th AOAPO, 3rd π-HuB Global Summit in conjunction with 13th CNHUPO Congress, hosted by the Proteomic Navigator of the Human Body Project(π-HuB), the Asia Oceania Human Proteomic Organization(AOHUPO), the Asia Oceania Agricultural Proteomics Organization(AOAPO), and the Chinese Human Proteome Organization(CNHUPO), and co-organized by the National Center for Protein Sciences(Beijing), Nanfang Hospital, Southern Medical University, State Key Laboratory of Medical Proteomics, and the International Academy of Phronesis Medicine(Guangdong), is scheduled to be held in Guangzhou from October 11 to 14, 2025. The theme of the congress is “Navigating the Protein Universe: Toward New Biology and Precision Medicine”.

BSI 专注于蛋白质组学与生物制药领域,依托机器学习与先进算法开发世界领先的质谱数据分析软件,助力加速生物学研究与药物研发进程。
我们有幸受邀于10月10-11日承办PEAKS Training Workshop,为您带来深度前沿的专业培训,带您走进深度蛋白质组学的世界!在此欢迎各位老师参与!
会议注册地址:http://aohupo2025.com/register (注册时请选择 PEAKS Online Training)
BSI, dedicated to proteomics and biopharmaceuticals, provides world-leading mass spectrometry data analysis software powered by machine learning and advanced algorithms to accelerate biological research and drug discovery.
We are honored to be invited to host the PEAKS Training Workshop on October 10–11, delivering in-depth, cutting-edge training to take you into the world of Deep Proteomics! We warmly welcome your participation!
Registered address:http://aohupo2025.com/register (注册时请选择 PEAKS Online Training)
Introduction
在过去的几年中,大规模的蛋白质组学研究使我们能够开始在蛋白质水平上了解表型。与人类基因组中大约 20,000 个蛋白质编码基因相比,人体内有超过 100,000 种不同的蛋白质,并且由于可变剪接以及转录后和翻译后加工,还存在数十万种 proteoform。多个课题研究表明蛋白质形态比其相应的蛋白质更好地描述蛋白质水平的生物学并且是更具体的分化指标。人工智能(AI)模型的赋能带来了高通量蛋白质组学的革命。
本次为期两天的 PEAKS 培训课程,将介绍 AI 模型在高通量蛋白质组学中的应用;展示如何针对多种互补的质谱方法,结合数据库搜索和从头测序的数据分析,达到在proteoform水平上的深度覆盖。无论是对于刚刚进入AI赋能的蛋白质组领域的新手,还是有经验的大队列样本的蛋白质组学研究,都非常适合参加这个培训。
Over the past few years, large-scale proteomics efforts have allowed us to begin to understand phenotype at a protein level. In contrast to about 20,000 protein-coding genes in the human genome, there are over 100,000 different proteins and, as a result of alternative splicing, hundreds of thousands of protein isoforms (variants) in the human body. However, proteins function in the context of modifications that include alternative splicing and posttranscriptional and posttranslational processing. Proteoforms better describe protein-level biology and are more specific indicators of differentiation than their corresponding proteins. It comes the revolution in high-throughput proteomics with artificial intelligence (AI) models.
In PEAKS Online training workshop, we are going to introduce AI models for high-throughput proteomics with deep coverage at proteoform level, by integrate alternative MS approaches with complementary database search and de novo sequencing data analysis. This training is highly suitable for both newcomers who have just entered the AI-empowered proteomics field and experienced researchers engaged in proteomics studies of large cohort samples.
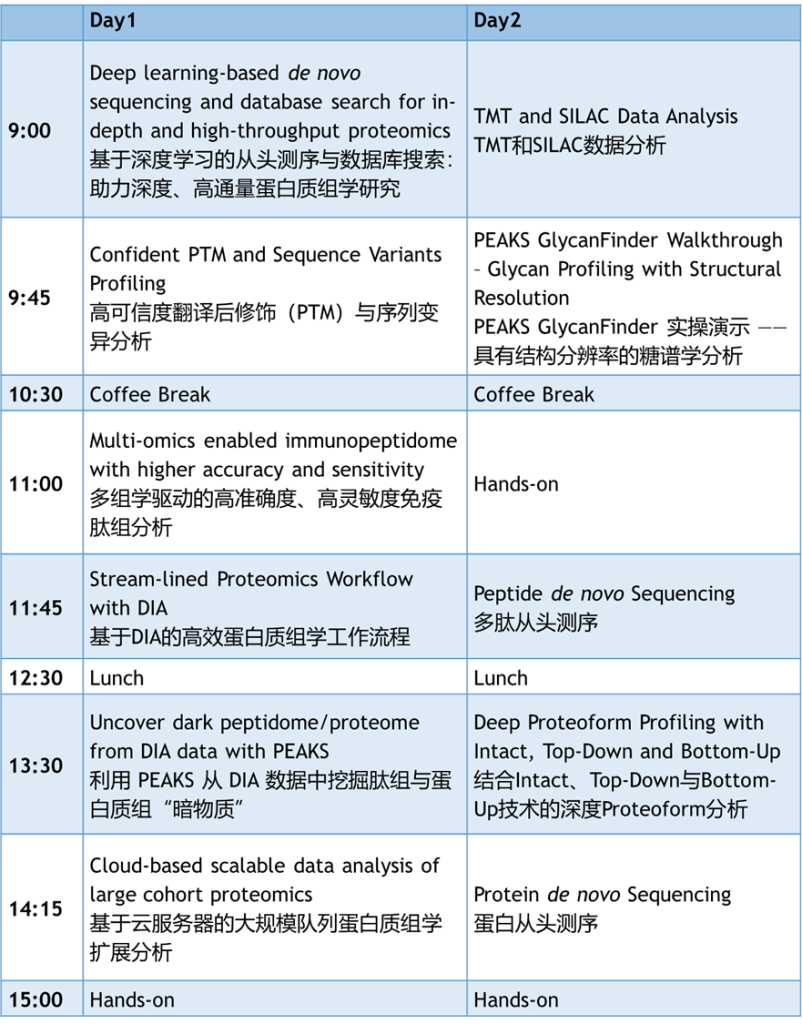
 基于深度学习的从头测序与数据库搜索:助力深度、高通量蛋白质组学研究(Deep learning-based de novo sequencing and database search for in-depth and high-throughput proteomics)
基于深度学习的从头测序与数据库搜索:助力深度、高通量蛋白质组学研究(Deep learning-based de novo sequencing and database search for in-depth and high-throughput proteomics)
整合数据库搜索与从头测序技术,并结合多种酶解策略,可实现蛋白质组的深度覆盖–覆盖度可达到 1.5 万个蛋白组中的 100 万条独特肽段,平均序列覆盖率约为 80%。
Integrating database search and de novo sequencing and combining multiple enzyme digests facilitated deeper proteome coverage up to a million unique peptides from 15,000 protein groups, with a median sequence coverage of approximately 80%.
高可信度翻译后修饰(PTM)与序列变异分析(Confident PTM and Sequence Variants Profiling)
借助基于人工智能驱动的评分模型,PEAKS 在鉴定翻译后修饰(PTM)与序列变异时可实现超高可信度,有效解决了在低丰度修饰或序列变异检测中常见的灵敏度与准确性问题。
Leveraging AI-powered scoring models, PEAKS achieves ultra-high confidence in identifying post-translational modifications (PTMs) and sequence variants, addressing the common issue of sensitivity and accuracy in low-abundance modification or variant detection.
多组学驱动的高准确度、高灵敏度免疫肽组分析(Multi-omics enabled immunopeptidome with higher accuracy and sensitivity)
将LC-MS/MS数据与下一代测序(NGS)结果相结合,PEAKS 可实现全面的免疫肽组分析 —— 突破单一技术手段的局限,确保精准鉴定主要组织相容性复合体(MHC)结合肽,为癌症免疫治疗研究提供支持。
Integrating LC-MS/MS data with next-generation sequencing (NGS) results, PEAKS enables comprehensive immunopeptidome profiling—overcoming the limitation of single-technology approaches and ensuring accurate identification of MHC-bound peptides for cancer immunotherapy research.
基于DIA的高效蛋白质组学工作流程(Stream-lined Proteomics Proteomics Workflow with DIA)
谱图库搜索与序列库搜索是DIA数据分析的两大核心方法。借助优化后的从头测序技术,PEAKS DIA 数据分析可实现蛋白质组的深度覆盖。
Spectral library search and library-free search are the two major approaches for DIA data analysis. Enhanced by de novo sequencing, PEAKS DIA data analysis provides you deep coverage.
利用 PEAKS 从 DIA 数据中挖掘肽组与蛋白质组“暗物质”(Uncover dark peptidome/proteome from DIA data with PEAKS)
除谱图库搜索与直接数据库搜索外,我们提出一种新型计算方法 —— 可直接从复杂 DIA 图谱中鉴定肽序列变异体与新肽段,同时严格控制假发现率(FDR)。
In addition to library search and direct database search, we present a novel computational method to identify peptide sequence variants and novel peptides directly and solely from complex DIA spectra while rigorously controlling the false discovery rate.
 结合Intact,Top-Down与Bottom-Up技术的深度Proteoform分析(Deep Proteoform Profiling with Intact, Top-Down and Bottom-Up)
结合Intact,Top-Down与Bottom-Up技术的深度Proteoform分析(Deep Proteoform Profiling with Intact, Top-Down and Bottom-Up)
通过整合Intact、Top-Down(TD),与Bottom-Up(BU)技术,PEAKS 可实现全面的Proteoform表征(包括亚型、翻译后修饰组合)—这一突破解决了单一方法工具无法充分解析蛋白质组复杂性的难题。
By integrating intact protein analysis, Top-Down (TD), and Bottom-Up (BU) approaches, PEAKS enables comprehensive proteoform characterization (including isoforms, PTM combinations)—a breakthrough for understanding proteome complexity that single-method tools cannot achieve.
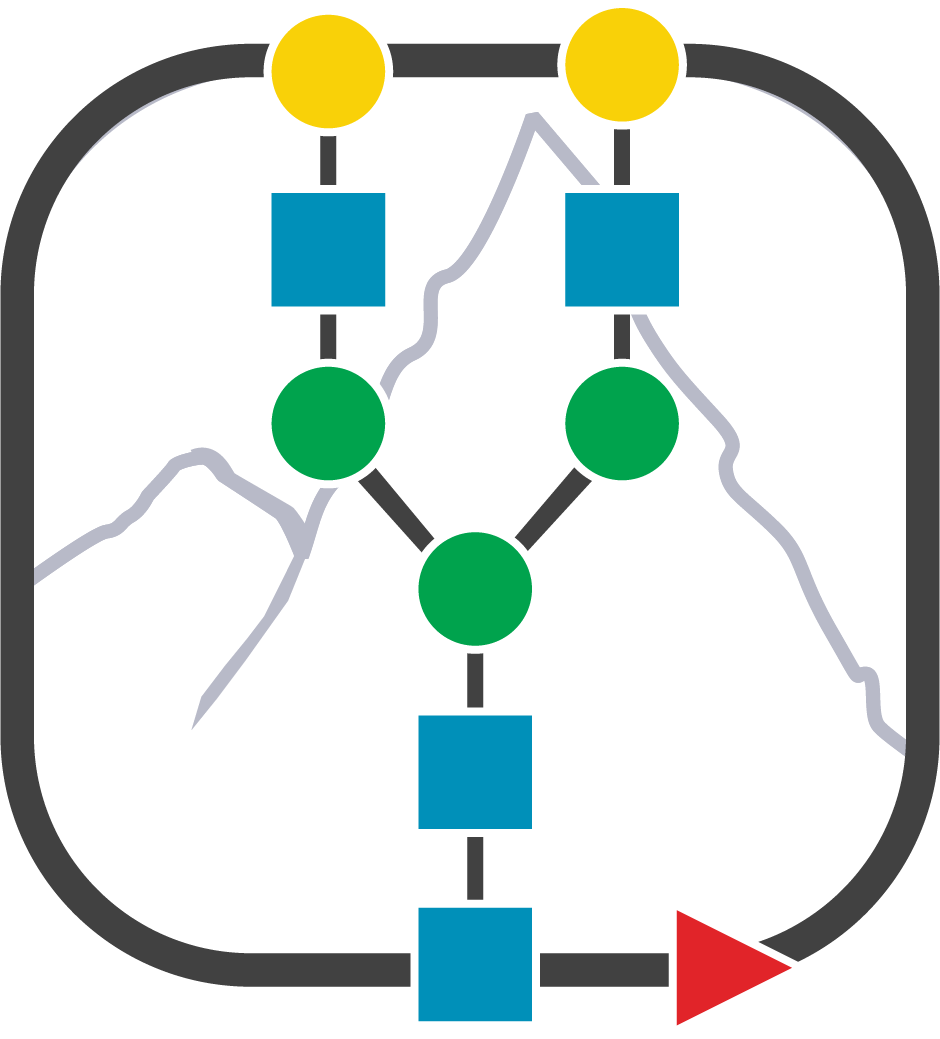 PEAKS GlycanFinder 实操演示 — 具有结构分辨率的糖谱学分析(PEAKS GlycanFinder Walkthrough – Glycan Profiling with Structural)
PEAKS GlycanFinder 实操演示 — 具有结构分辨率的糖谱学分析(PEAKS GlycanFinder Walkthrough – Glycan Profiling with Structural)
与只能检测糖基是否存在的通用工具不同,GlycanFinder 可实现糖链结构解析(如连接方式、分支结构),解决了在糖蛋白组学研究中表征复杂糖链结构的关键挑战。
Unlike generic tools that only detect glycan presence, GlycanFinder provides structural-level resolution of glycans (e.g., linkage, branching), solving the key challenge of characterizing complex glycan structures in glycoproteomics research.
 基于云服务器的大规模队列蛋白质组学扩展分析(Cloud-based scalable data analysis of large cohort proteomics)
基于云服务器的大规模队列蛋白质组学扩展分析(Cloud-based scalable data analysis of large cohort proteomics)
PEAKS Online 云平台可实现大规模队列项目的自动化分析,支持深度蛋白质组学与蛋白质基因组学分析,并能满足发现型与靶向型质谱技术的分析通量需求。
PEAKS Online enables the automation of large-scale cohort project with in-depth proteomics and proteogenomics analyses and throughput of discovery and targeted mass-spectrometry-based technologies.
蛋白质从头测序(Protein de novo Sequencing)
此外,每个专题报告后将设置问答环节,解答参会者遇到的具体问题。无论您是蛋白质组学数据分析新手,还是希望精进专业技能的资深研究者,本次沉浸式PEAKS Training Workshop将为您提供实用工具,助力优化质谱工作流程,充分发挥PEAKS在不依赖数据库分析、整合多项技术及高可信度检测复杂蛋白质组特征方面的独特优势。
Additionally, Q&A sessions will be held after each presentation to address participants’ specific challenges. Whether you are new to proteomics data analysis or seeking to refine your expertise, this immersive workshop will equip you with practical tools to optimize MS workflows—leveraging PEAKS unique strengths in database-independent analysis, multi-technology integration, and high-confidence detection of complex proteomic features.
如果您想提前了解我们的产品,可以点击【咨询了解】,提交您的相关信息。
Want to know more? Request more details We’ll be happy to answer any of your inquiries today.