

自下而上的蛋白质组学完整解决方案
PEAKS® Studio 提供完整的自下而上的蛋白质组学解决方案,具有更高的准确性、灵敏度和速度。能够全面支持主流质谱仪器的数据依赖采集(DDA)和数据非依赖采集(DIA)原始数据,并针对多种应用场景更新了相应的工作流程(如经典和非经典多肽/蛋白质的深度鉴定),为用户提供全面的解决方案,助力相关研究迈向新高度!
One-Stop
Discovery and Targeted Proteomics
Comprehensive
and Confident
DDA Solutions

High Accuracy and Sensitivity DIA Solutions
High Precision
PRM Solutions
de novo and
DeepNovo
Algorithms
Vendor Neutral
Software
联系我们获取PEAKS Studio 13.5 !
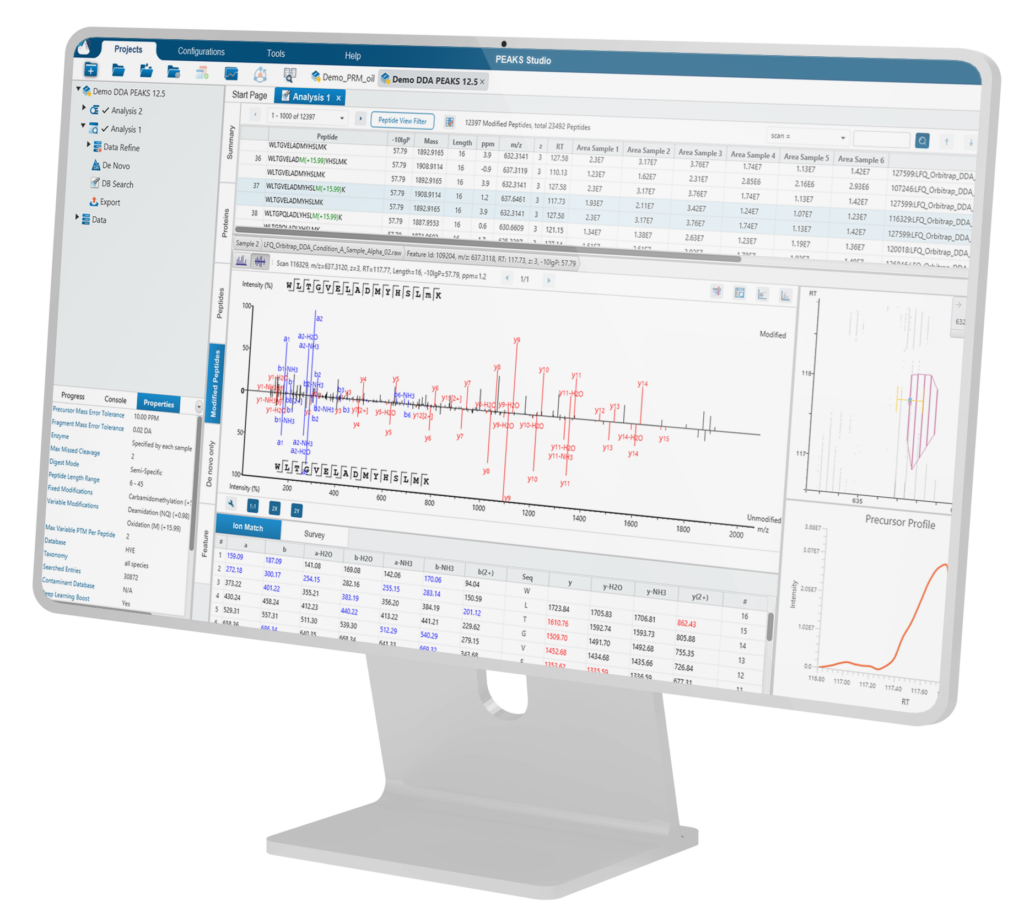
多引擎驱动的DDA/DIA专业解析
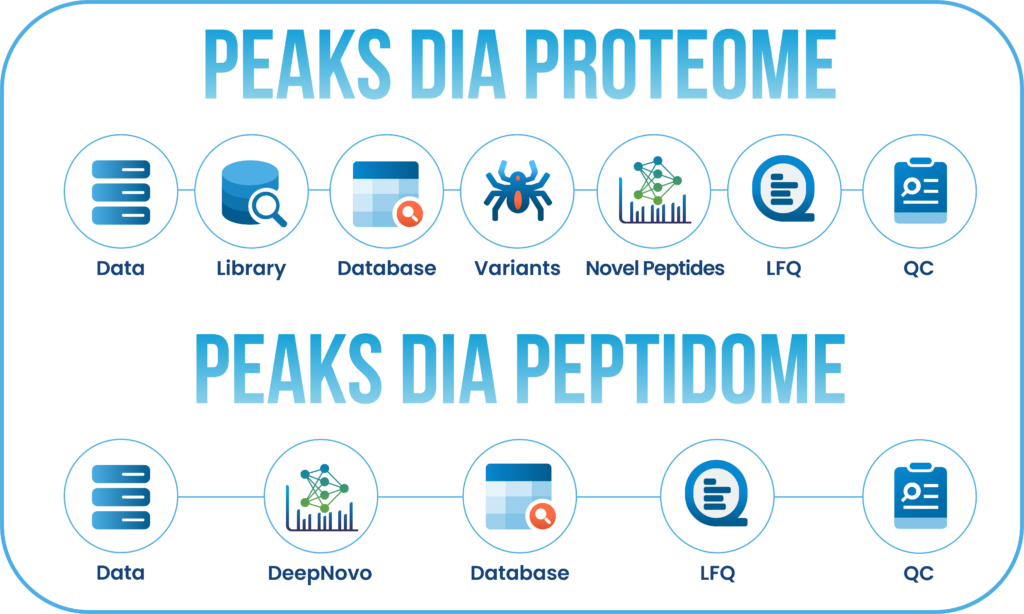
为了便于使用,PEAKS Studio将DDA和DIA数据分析各自精简为两个集成的工作流:蛋白质组学(Proteome)和肽组学(DeepNovo Peptidome),用户根据分析需求选择后,逐步完成参数设置即可。
Proteome工作流能够支持传统的蛋白质和内源性多肽定性和定量分析,结果聚焦于蛋白质水平。而肽组学工作流程利用基于深度学习算法的DeepNovo从头测序技术,结合数据库搜索与序列变异分析,实现肽段水平的深度挖掘分析。
用户可自定义分析流程,可根据分析需求在任意步骤选择提交分析,并可在此分析基础上添加或修改其他步骤。分析结果将以直观的结果节点形式展示,便于用户解读、探索和验证数据。

核心功能
DIA Workflow

LC/MS Data
Refine View

Feature-Based Identification
DeepNovo
Peptidome
Confident
PTM/Mutations
Quality Control (QC) Function
DIA Feature
View
Quantification
View

Hybrid DIA
and PRM/MRM
Protein &
Peptide View
整合直接序列数据库搜索的一体化DIA工作流
PEAKS® Studio的DIA Proteome工作流整合了谱图库搜索、直接数据库搜索、从头测序、PTM分析与序列变异分析多个分析功能,提供独具优势的全面分析,最大化提升肽段和蛋白质的鉴定深度。
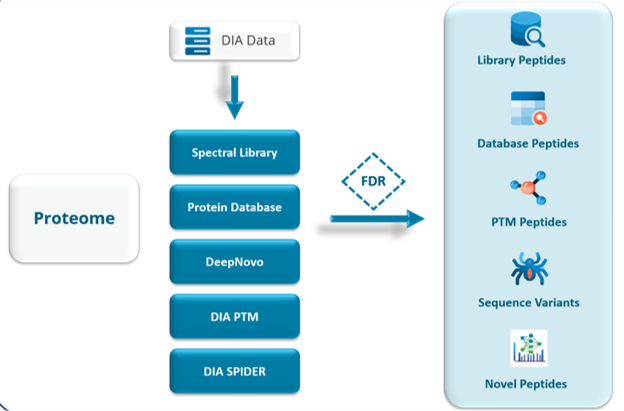
- 在勾选谱图库的情况下,PEAKS首先将所有的谱图进行基于谱图库的检索,将通过FDR阈值的多肽输出。
- 对于未能与谱图库匹配到的二级谱,可以进一步使用理论蛋白质序列数据库开展直接数据库预测匹配。
- 支持DIA de novo分析可以辅助鉴定全新肽段、序列变异及未预设类型的翻译后修饰。
- 融合以谱图为中心与以肽段为中心的两类分析策略,率先实现了不依赖谱图库的翻译后修饰全景图谱解析。
针对经谱图库与数据库搜索鉴定得到的肽段,可开展无标记定量分析,用于探究多组实验条件下蛋白质与肽段的相对丰度变化规律。
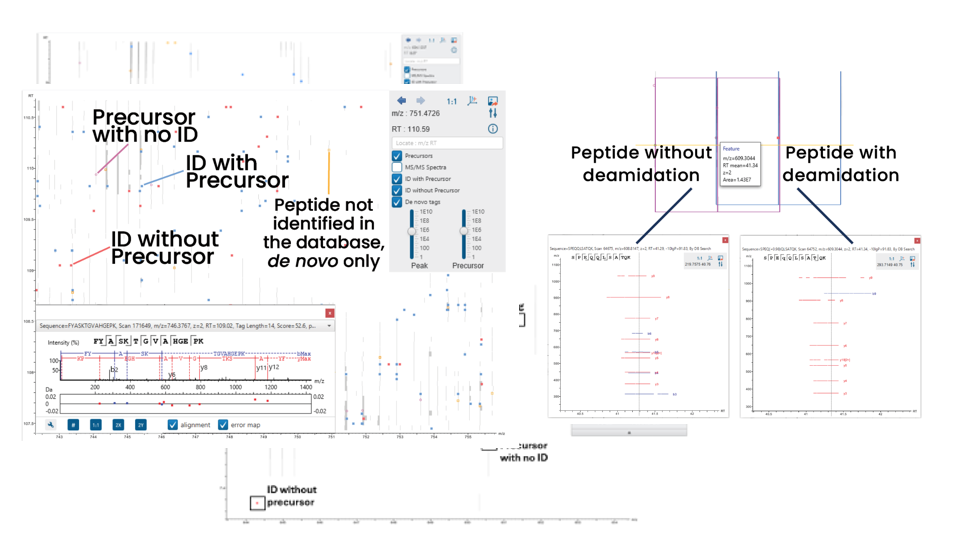
LC/MS Data Refine视图
用户可在LC/MS图谱上轻松可视化母离子(有或无Identification的母离子均会展示),以及从头测序标签,以改进结果验证。
对于一个给定的肽段,可以在多肽列表和LC/MS视图之间无缝切换。点击一个或多个鉴定结果即可显示并比较支持的碎片离子,这便于验证重叠的肽段鉴定。
支持的碎片离子还会在肽段选项卡的LC/MS谱图中显示。用户也可点击LC/MS图谱查看鉴定结果。
基于特征峰的定性分析
- 基于MS1特征峰的鉴定可提高灵敏度和肽鉴定效率。
- 专为DDA设计,提高了数据分析的重现性。
- 整合了数据库搜索和从头测序,实现深度蛋白质组学。
- PEAKS DDA的启用深度学习增强功能,使多肽的鉴定达到最大化。
- 对于未匹配到数据库序列的谱图,如果有评分较高的 de novo 标签,可以执行多轮搜索、PEAKS PTM、Open PTM以及序列变体等分析。
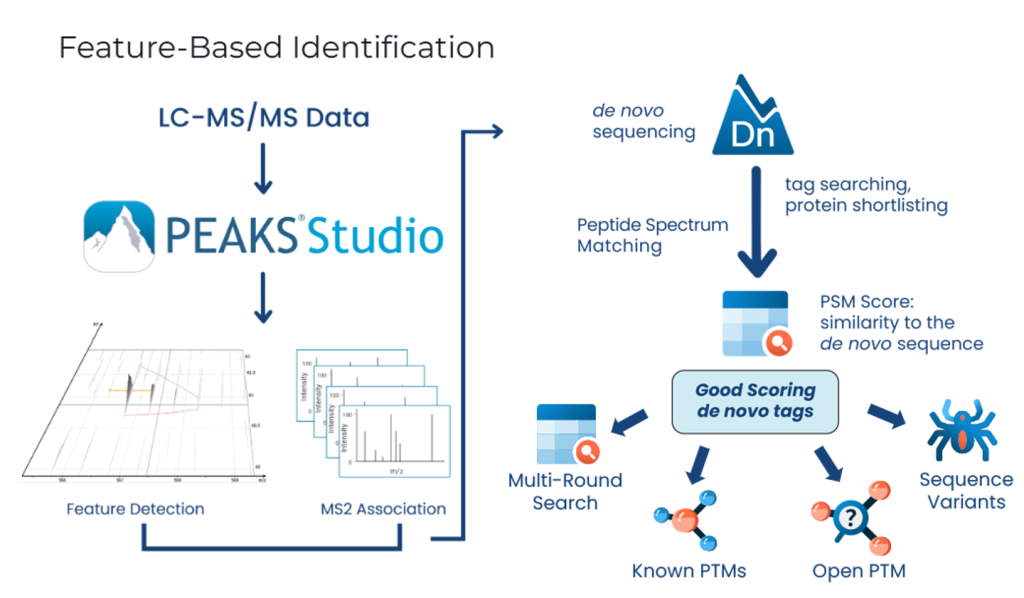
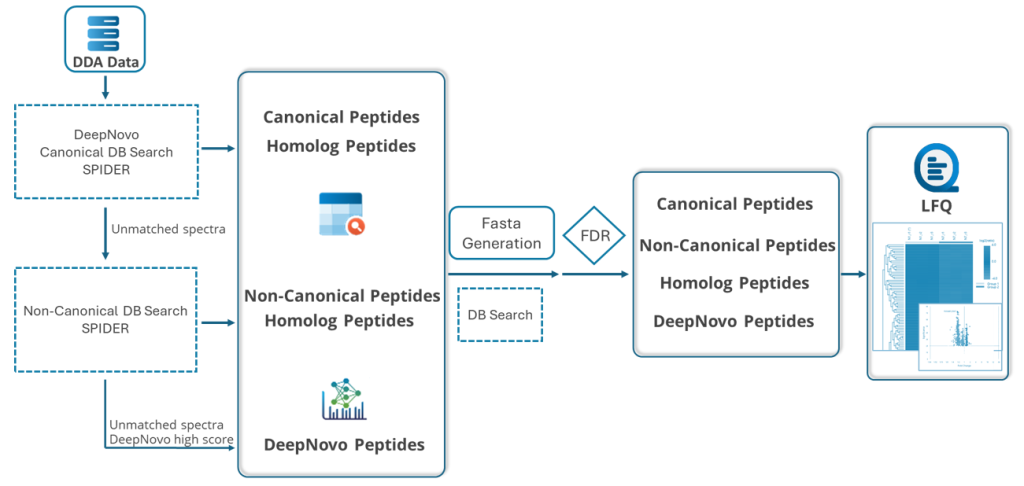
PEAKS DeepNovo多肽组学:先进的免疫肽组学解决方案
DeepNovo肽组学工作流旨在通过整合全面基因表,弥合蛋白质组学与基因组学。其DDA工作流支持非经典参考序列检索,可鉴定标准经典参考数据库通常遗漏的变异序列与修饰序列。DIA肽组学支持谱图库、目标肽段列表与spiked重标肽段列表三种数据库分析,最终导出候选肽段。
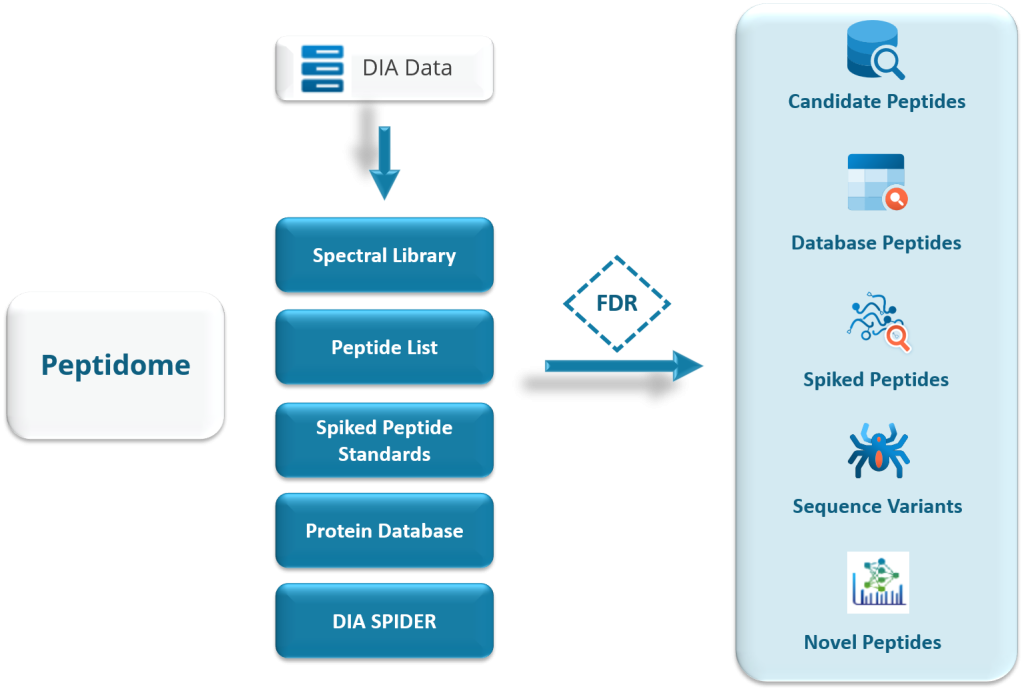
更高水平的置信度:精确到氨基酸的可信翻译后修饰/突变位点鉴定
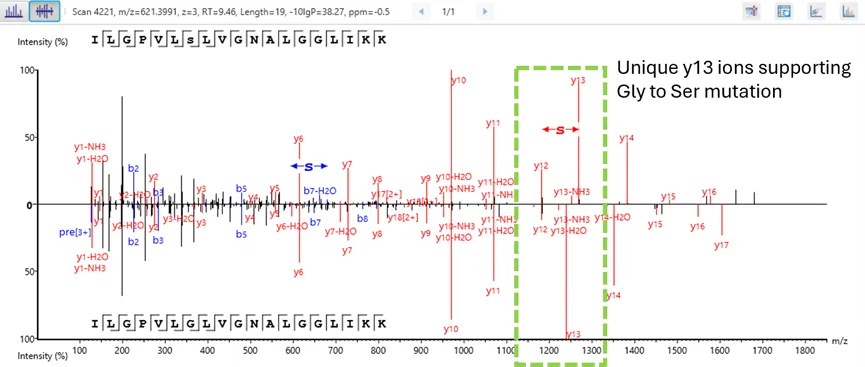
PEAKS PTM和SPIDER功能通过氨基酸碎片离子的直接证据,高精度识别PTM和突变位点。
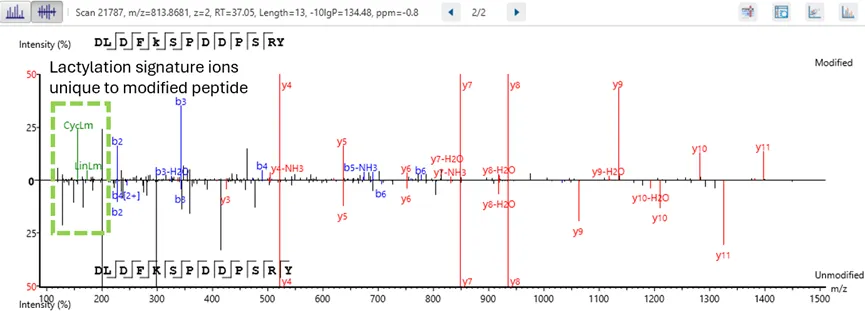
可以帮助研究人员精准确定蛋白质中的特定修饰和突变,从而准确理解蛋白的功能和调控机制,更深入地了解蛋白质动力学和疾病机制。并且对于推进对生物过程的理解和制定有针对性的治疗方案至关重要。
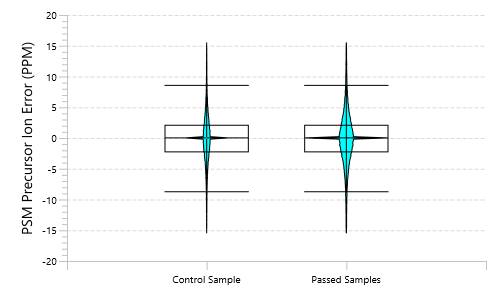
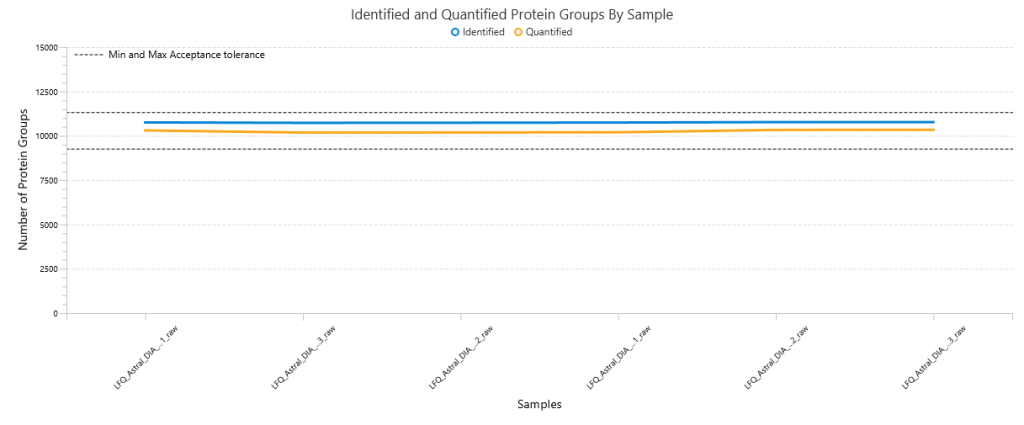
质量控制(QC)功能:从原始数据到结果的深入分析
使用PEAKS® Studio中的质量控制(QC)功能,用户可以评估原始数据和结果的统计信息,并获得对LC-MS采集的关键指标。这个自动化工具专为DDA和DIA数据而设计,可提供用于判断数据质量的指标因素,并对实验设置进行评估。
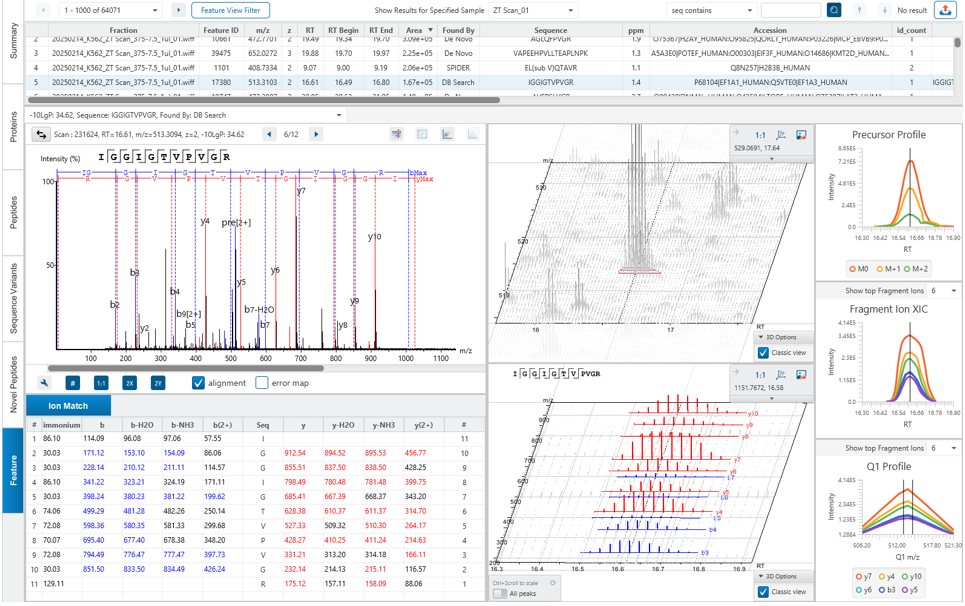
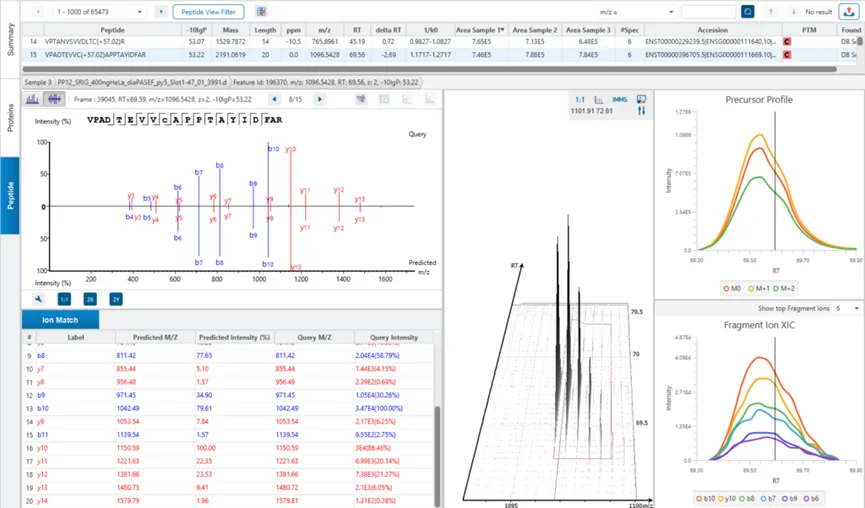
DIA Feature View
PEAKS®的DIA Feature可视化展示提供了DIA数据解析结果的更丰富的信息,使用户能够便利的查看、验证和确认母离子。不管有没有定性信息,均展示完整的碎片离子归属,Mirror plot会显示预测谱图与实际检测谱图的相关性,同时提供MS1与MS2双维度特征视图。
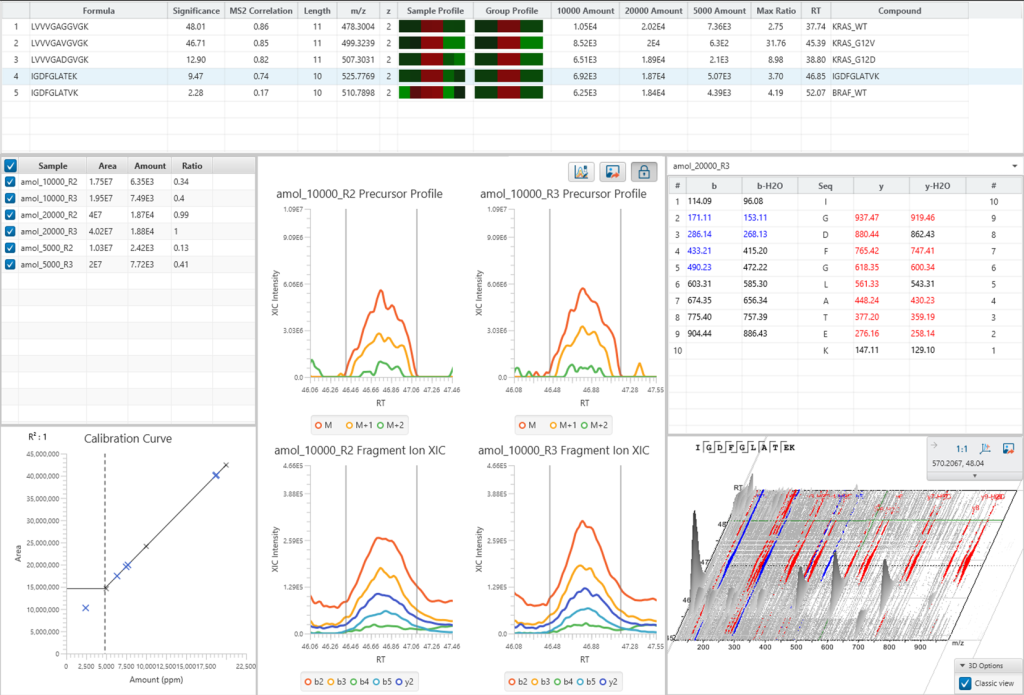
Quantification View
PEAKS®Studio中的定量模块PEAKS Q,直接在定性工作流后加入定量分析步骤即可获得在不同样品中,蛋白质丰度的相对含量值。通过PEAKS PTM和SPIDER搜索找到的肽段也会被包含在定量分析结果中。
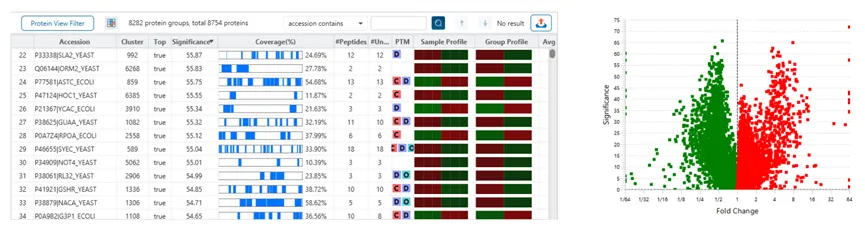
如果选择了“Feature-based”的定量,LFQ结果将包含一个新的“de novo only”选项卡,其中包含与数据库不匹配的肽段的定量结果。
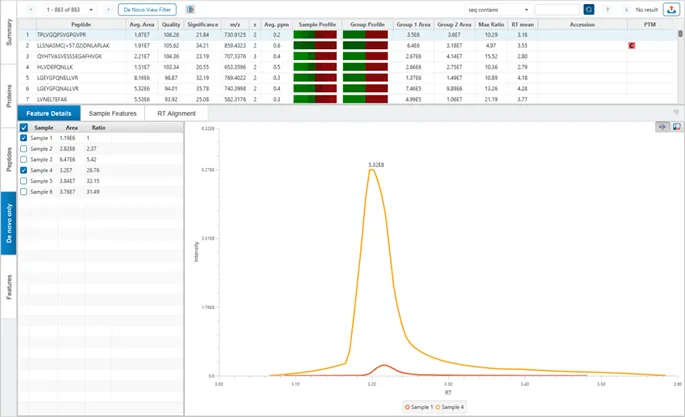
Hybrid DIA
Thermo的Hybrid-DIA数据,仅在PEAKS® Studio中可以分析,该采集方法结合了靶向和发现驱动的方法,使其成为临床蛋白质组学应用的理想选择。
Hybrid-PRM/DIA是一种新的数据采集策略,重标参考肽被用作触发离子,通过智能触发并行反应监测(PRM)与DIA采集,将临床样本的生物信息智能、全面地数字化。
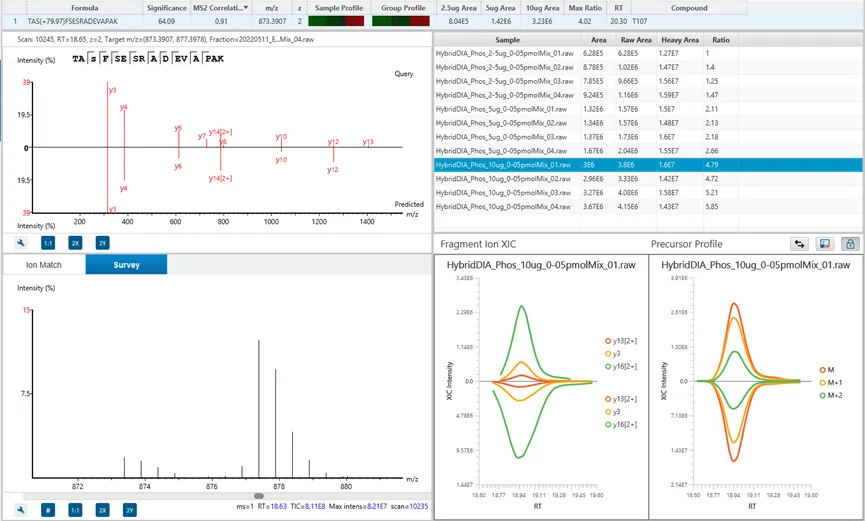
PRM/MRM
PRM靶向定量工作流可对复杂生物样本中的特定肽段实现精准可靠的定量分析。
PEAKS Studio 新增手动配置选项:支持自主筛选肽段碎片离子、划定保留时间区间,所有参数调整均可在最终确认前实时预览。全新的带注释二级质谱数据视图,也大幅简化了肽段碎片离子的可视化验证流程。
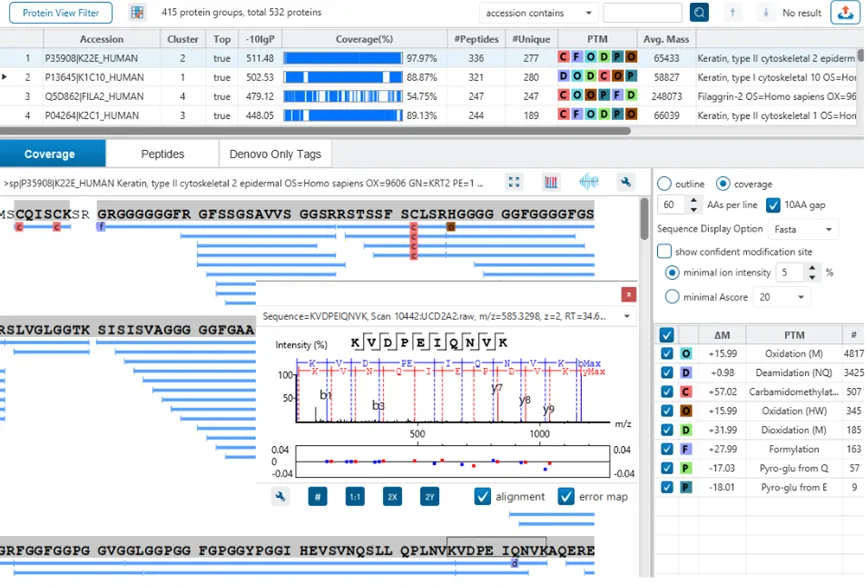
The Protein View
蛋白质视图在DDA和DIA工作流程中展示了复杂生物样品的蛋白谱。对于每个蛋白质,Coverage视图显示了一个包含谱图注释信息的肽图,用于结果的验证。使用PEAKS传统的从头测序辅助数据库搜索的方法,用户可以轻松地在蓝条状图中查看与参考序列数据库匹配一致的多肽序列,而灰色的条状图表示de novo only与参考序列库部分匹配的序列标签。
The Peptide View
多肽视图提供了多肽鉴定结果的列表,并且包含了MS1的丰度信息,对每一个修饰肽段,修饰位点的置信度信息(Ascore)也会显示在这里。
无与伦比的客户服务支持
![]() 快速专业的技术响应
快速专业的技术响应
我们内部的专业科学家团队将及时回应您的PEAKS技术咨询,确保您的工作流程和研究进度不受任何阻碍。
![]() 持续更新的教程资源库
持续更新的教程资源库
提供详尽的分步操作指南、流程演示和在线研讨会,帮助您和团队充分发挥PEAKS Studio的分析潜能。
![]() 基于用户反馈的持续优化
基于用户反馈的持续优化
我们认真倾听用户声音。您的建议与需求将直接推动我们后续版本的开发和平台功能改进,确保软件始终满足蛋白质组学研究的前沿需求。

授权信息
PEAKS Studio 可以根据您实验室的使用需求选择授权版本
- Desktop License–24线程, 最多可以处理达到CPU的24线程
- Workstation License–48线程,最多可以处理达到CPU的48线程
系统要求
PEAKS® Studio 13.1建议安装在 Windows 10或更高版本的64 位Windows 操作系统上。
推荐配置
Desktop License: 30+线程处理器、64GB+of RAM以及兼容GPU(如下所述)
Workstation License:60+线程处理器、128GB+RAM以及兼容 GPU(如下所述),如 Intel Core i7/i9/Xeon或AMD Ryzen 7/9/Threadripper处理器
如需运行DeepNovo,需要机器配备NVIDIA CUDA计算能力≥8 且≥8GB内存的GPU。
如需运行DIA Database Search,建议机器配备具有NVIDIA CUDA 计算能力≥5 且≥8GB 专用内存的GPU。
GPU 驱动必须更新到 CUDA 12.3 或更高版本。
References & Resources
References
- Tran NH, Qiao R, Xin L, Chen X, Liu C, Zhang X, Shan B, Ghodsi A, Li M, Deep learning enables de novo peptide sequencing from data-independent-acquisition mass spectrometry, Nat. Methods, 16, 63–66 (2019). https://doi.org/10.1038/s41592-018-0260-3
- Tran NH, Zhang X, Xin L, Shan B, Li M. De novo peptide sequencing by deep learning. Proc. Natl. Acad. Sci. U.S.A. 114, 8247-8252 (2017). https://doi.org/10.1073/pnas.1705691114
Resources
- PEAKS Studio 13 Brochure
- Application Note: The Proteomics Continuum: Discovery, Definition, and Validation-PEAKS solution for translational medicine research
- Application Note: Determination of unknown PTMs and increased protein sequence coverage from high temperature acidic enzyme digests
- Application Note: From Discovery to Targeted Proteomics: A Complete Workflow for MRMHR-based Peptide Quantitation